
Mới đây, NVIDIA đã cho ra mắt phiên bản H100 PCIe đặc biệt, nhắm vào thị trường đặc thù: triển khai mô hình ngôn ngữ lớn (LLM). Nó là 2 chiếc H100 PCIe được kết nối với nhau qua NVLink, Cặp GPU kép kết hợp lại thành bộ nhớ HBM3 lên đến 188GB – 94GB trên mỗi card – cung cấp nhiều VRAM nhất trên mỗi GPU NVIDIA cho đến hiện giờ, ngay cả trong với dòng H100.

Động lực chính cho mã sản phẩm này là một thị trường ngách đặc thù và đang hót nhất hiện nay: dung lượng bộ nhớ và mô hình ngôn ngữ lớn như GPT. Các mô hình ngôn ngữ lớn như GPT family cực kỳ khát dung lượng VRAM, ngay cả các phiên bản 80GB cũng rất dễ bị đầy VRAM nhanh chóng. Do đó, NVIDIA đã chọn kết hợp một mã sản phẩm H100 mới cung cấp bộ nhớ HBM3e lớn hơn cho mỗi GPU so với các phiên bản H100 thông thường của họ.

Thông thường, các GPU GH100 đều đi kèm với 6 stack của bộ nhớ HBM – HBM2e hoặc HBM3 – với dung lượng 16GB mỗi stack. Tuy nhiên, vì lý do đẩy nhanh sản lượng sản xuất, NVIDIA chỉ bán các linh kiện H100 thông thường của họ với 5 trong số 6 stack HBM được bật. Vì vậy, mặc dù trên danh nghĩa H100 hỗ trợ tối đa 96GB VRAM trên mỗi GPU, nhưng chỉ có 80GB trên các SKU thông thường.

Ngược lại, H100 NVL là SKU được kích hoạt đầy đủ một cách bí ẩn với tất cả 6 stack được kích hoạt. Bằng cách kích hoạt stack HBM thứ 6, NVIDIA có thể truy cập bộ nhớ bổ sung và băng thông bộ nhớ bổ sung mà nó cung cấp. Nó sẽ có một số tác động quan trọng đến sản lượng, nhưng thị trường LLM rõ ràng là đủ lớn và sẵn sàng trả giá đủ cao cho các gói GH100 gần như hoàn hảo để khiến nó xứng đáng với thời gian của NVIDIA.
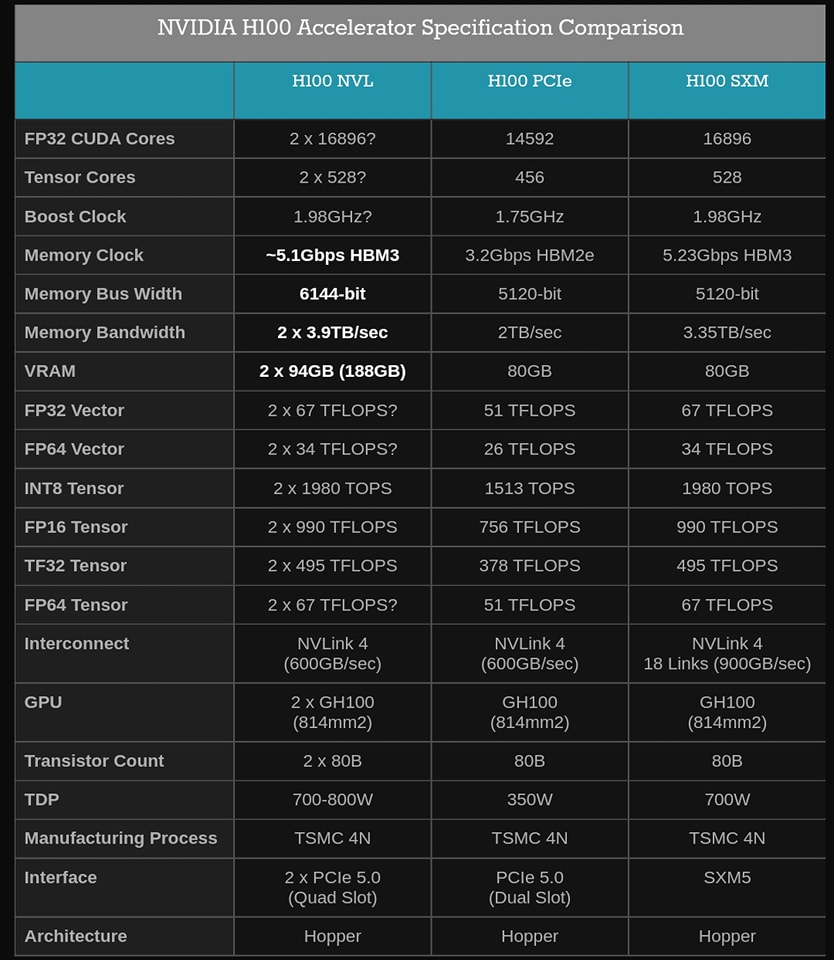
Cần lưu ý thêm rằng người dùng không thể tận dụng toàn bộ 96GB mỗi card. Thay vào đó, với tổng dung lượng bộ nhớ 188GB, họ nhận được 94GB hiệu quả cho mỗi card. Có thể cũng là vì lý do sản lượng, khiến NVIDIA và các hãng bộ nhớ có chút chậm trễ trong việc vô hiệu hóa các cell (hay layer) xấu trong stack bộ nhớ HBM3. Kết quả cuối cùng là SKU mới cung cấp thêm 14GB bộ nhớ cho mỗi GPU GH100, tăng 17,5% bộ nhớ. Trong khi đó, băng thông bộ nhớ tổng hợp cho card là 7,8TB/giây, tương đương với 3,9TB/giây đối với các bo mạch riêng lẻ.

Bên cạnh việc tăng dung lượng bộ nhớ, theo nhiều cách, các card riêng lẻ trong H100 NVL GPU kép/card kép lớn hơn trông rất giống phiên bản H100 PCIe. Trong khi H100 PCIe bình thường bị cản trở một tí do sử dụng bộ nhớ HBM2e chậm hơn, ít SM/lõi tensor hoạt động hơn và tốc độ xung nhịp thấp hơn, thì các số liệu hiệu suất lõi tensor mà NVIDIA đang trích dẫn cho H100 NVL đều ngang bằng với H100 SXM5, cho thấy rằng thẻ này có thể không bị cắt bớt hiệu năng như thẻ PCIe thông thường.
H100 NVL không phải là một GPU đơn lẻ mà là một bộ card kép. Bản thân phần cứng này dựa trên hai H100 có form-factor PCIe được kết nối với nhau bằng ba cầu nối NVLink 4. Về mặt vật lý, thiết kế này hầu như giống hệt với thiết kế H100 PCIe hiện có của NVIDIA – vốn đã có thể được ghép nối bằng cách sử dụng các cầu nối NVLink – vì vậy, sự khác biệt không nằm ở cấu tạo của 2 card 2, mà là ở chất lượng của silicon bên trong. Nói cách khác, ngày nay bạn có thể kết hợp các thẻ H100 PCie thông thường với nhau, nhưng nó sẽ không phù hợp với băng thông bộ nhớ, dung lượng bộ nhớ hoặc thông lượng tensor của H100 NVL.

Đáng ngạc nhiên, bất chấp các thông số kỹ thuật xuất sắc, TDP hầu như không thay đổi. H100 NVL là cặp card có công suất từ 700W đến 800W, chia nhỏ thành 350W đến 400W trên mỗi card, có yêu cầu TDP như H100 PCIe thông thường. Trong trường hợp này, NVIDIA có vẻ đang ưu tiên khả năng tương thích hơn là hiệu suất cao nhất, vì rất ít rack máy chủ có thể xử lý card PCIe trên 350W. Tuy nhiên, với các số liệu hiệu suất và băng thông bộ nhớ cao hơn, có thể thấy NVIDIA đã tìm cách tối ưu chỉ số hiệu quả năng lượng (hiệu năng/watt) tốt nhất có thể với mục đích sử dụng mô hình ngôn ngữ lớn.
Mặt khác, cấu hình của H100 NVL về cơ bản là một lựa chọn bất thường do ưu tiên chung của họ đối với các linh kiện SXM, nhưng đó là một quyết định có ý nghĩa trong bối cảnh khách hàng LLM cần gì. Các cụm H100 lớn dựa trên SXM có thể dễ dàng mở rộng quy mô lên tới 8 GPU, nhưng lượng băng thông NVLink khả dụng giữa hai GPU bất kỳ bị cản trở do nhu cầu đi qua NVSwitch. Đối với cấu hình chỉ hai GPU, việc ghép nối một bộ thẻ PCIe trực tiếp hơn nhiều, với liên kết cố định đảm bảo băng thông 600GB/giây giữa các card.
Nhưng lợi thế quan trọng nhất của phiên bản này là khách hàng có thể chỉ cần nâng cấp dễ dàng H100 NVL vào các máy chủ mới hoặc lên các máy chủ/Workstation PC họ đang có qua những khe PCIe thông dụng, giống y hệt cấu hình PC game thủ thay vì phải lắp ráp khó khăn như các phiên bản SXM.
Tất cả đã cho thấy, NVIDIA đang chào hàng H100 NVL khi cung cấp thông lượng suy luận GPT3-175B gấp 12 lần dưới dạng HGX A100 thế hệ mới nhất (8 H100 NVL so với 8 A100). NVIDIA cho biết OpenAI hiện đang sử dụng DGX A100 cho ChatGPT có thể thay thế tối đa 10 hệ thống DGX A100 bằng bốn cặp NVIDIA H100 NVL để thực hiện suy luận. Đối với những khách hàng đang tìm cách triển khai và mở rộng quy mô hệ thống của họ cho khối lượng công việc LLM càng nhanh càng tốt, chắc chắn đây sẽ là miếng bánh béo bở không thể bỏ qua. Như đã lưu ý trước đó, H100 NVL không mang lại bất kỳ điều gì mới về các tính năng kiến trúc – phần lớn hiệu suất gia tăng ở đây đến từ các Transformer Engine mới của kiến trúc Hopper – nhưng H100 NVL sẽ phục vụ một phân khúc cụ thể với tùy chọn là H100 PCIe nhanh nhất và tùy chọn có nhóm bộ nhớ GPU lớn nhất.
Cuối cùng, theo NVIDIA, card H100 NVL sẽ bắt đầu được bán ra vào nửa cuối năm nay. Công ty không công bố giá, nhưng đối với những gì về cơ bản nó là bộ GH100 đầu bảng, chúng ta có thể kỳ vọng chúng sẽ có mức giá cực cao ngay cả với những công ty tập đoàn lớn. Đặc biệt là khi sự bùng nổ của việc sử dụng LLM đang biến thành một cơn sốt vàng mới cho thị trường GPU máy chủ.




